11 June 2019
Using Causal Profiling to Optimize the Go HTTP/2 Server
Introduction
If you've been keeping up with this blog, you might be familiar with Causal profiling, a profiling method that aims to bridge the gap between spending cycles on something and that something actually helping improve performance. I've ported this profiling method to Go and figured I'd turn it loose on a real piece of software, The HTTP/2 implementation in the standard library.
HTTP/2
HTTP/2 is a new version of the old HTTP/1 protocol which we know and begrudgingly tolerate. It takes a single connection and multiplexes requests onto it, reducing connection establishing overhead. The Go implementation uses one goroutine per request and a couple more per connection to handle asynchronous communications, having them all coordinate to determine who writes to the connection when.
This structure is a perfect fit for causal profiling. If there is something implicitly blocking progress for a request, it should pop up red hot on the causal profiler, while it might not on the conventional one.
Experiment setup
To grab measurements, I set up an synthetic benchmark with an HTTP/2 server and client. The server takes the headers and body from the Google home page and just writes it for every request it sees. The client asks for the root document, using the client headers from firefox. The client limits itself to 10 requests running concurrently. This number was chosen arbitrarily, but should be enough to keep the CPU saturated.
Causal profiling requires us to instrument the program. We do this by setting Progress markers, which measure the time between 2 points in the code. The HTTP/2 server uses a function called runHandler that runs the HTTP handler in a goroutine. Because we want to measure scheduler latency as well as handler runtime, we set the start of the progress marker before we spawn the goroutine. The end marker is put after the handler has written all its data to the wire.
To get a baseline, let's grab a traditional CPU profile from the server, yielding this profiling graph:
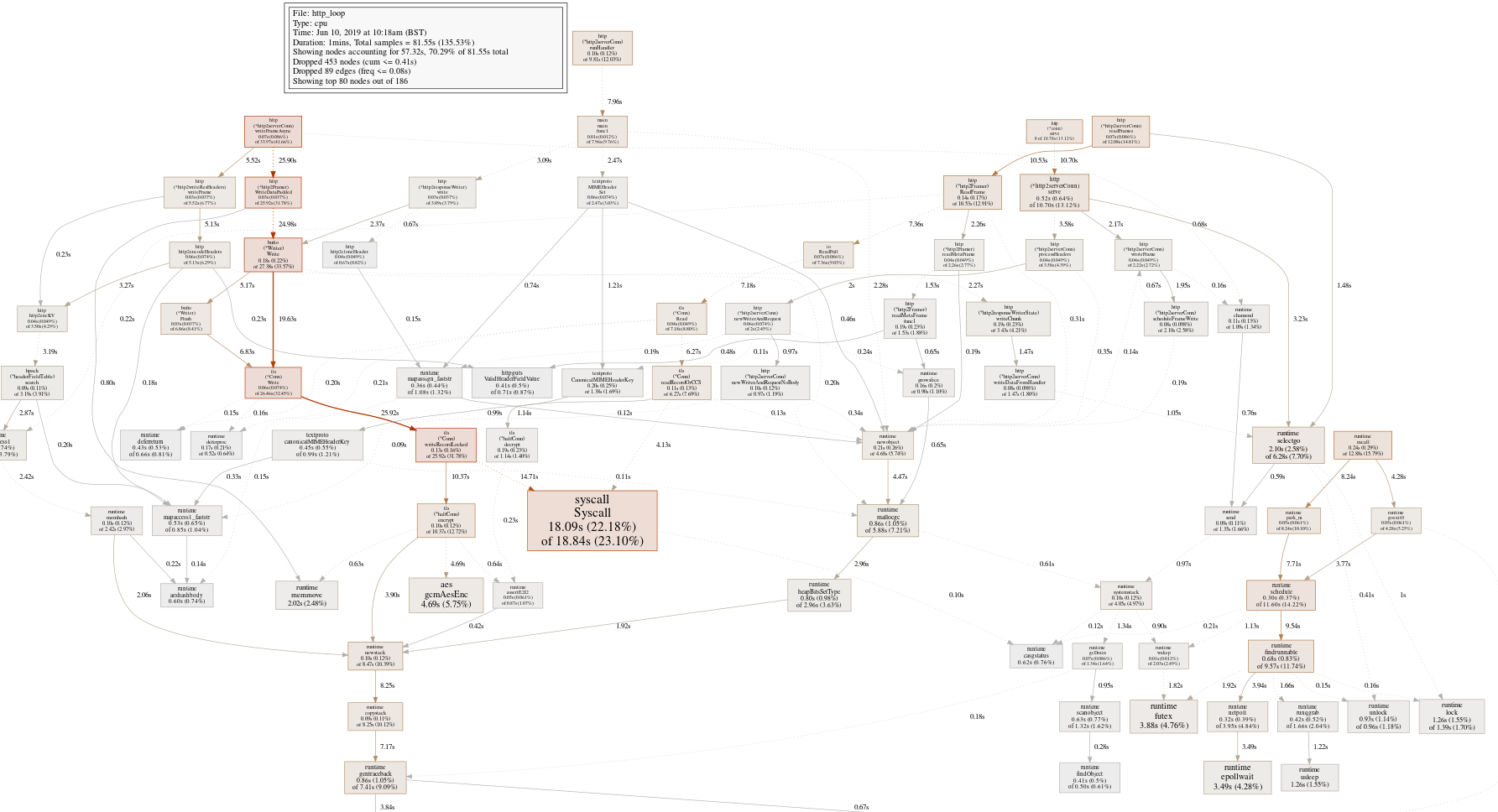
OK, that's mostly what you'd expect from a large well-optimized program, a wide callgraph with not that many obvious places to sink our effort into. The big red box is the syscall leaf, a function we're unlikely to optimize.
The text gives us a few more places to look, but nothing substantial
(pprof) top
Showing nodes accounting for 40.32s, 49.44% of 81.55s total
Dropped 453 nodes (cum <= 0.41s)
Showing top 10 nodes out of 186
flat flat% sum% cum cum%
18.09s 22.18% 22.18% 18.84s 23.10% syscall.Syscall
4.69s 5.75% 27.93% 4.69s 5.75% crypto/aes.gcmAesEnc
3.88s 4.76% 32.69% 3.88s 4.76% runtime.futex
3.49s 4.28% 36.97% 3.49s 4.28% runtime.epollwait
2.10s 2.58% 39.55% 6.28s 7.70% runtime.selectgo
2.02s 2.48% 42.02% 2.02s 2.48% runtime.memmove
1.84s 2.26% 44.28% 2.13s 2.61% runtime.step
1.69s 2.07% 46.35% 3.97s 4.87% runtime.pcvalue
1.26s 1.55% 47.90% 1.39s 1.70% runtime.lock
1.26s 1.55% 49.44% 1.26s 1.55% runtime.usleepMostly runtime and cryptography functions. Let's set aside cryptography, since it will already have been optimized a lot.
Causal Profiling to the rescue
Before we get to the profiling results from causal profiling, it'd be good to have a refresher on how it works. When causal profiling is enabled, a series of experiments are performed. An experiment starts by picking a call-site and some amount of virtual speed-up to apply. Whenever that call-site is executed (which we detect with the profiling infrastructure), we slow down every other executing thread by the virtual speed-up amount.
This would seem counter-intuitive, but since we know how much we slowed down a program when we take our measurement from the Progress marker, we can undo the effect, which gives us the time it would have taken if the chosen call-site was sped up. For a more in-depth look at causal profiling, I suggest you read my other causal profiling posts and the original paper.
The end result is that a causal profile looks like a collection of call-sites, which were sped up by some amount and as a result changed the runtime between Progress markers. For the HTTP/2 server, a call-site might look like:
0x4401ec /home/daniel/go/src/runtime/select.go:73 0% 2550294ns 20% 2605900ns +2.18% 0.122% 35% 2532253ns -0.707% 0.368% 40% 2673712ns +4.84% 0.419% 75% 2722614ns +6.76% 0.886% 95% 2685311ns +5.29% 0.74%
For this example, we're looking at an unlock call within the select runtime code. We have the amount that we virtually sped up this call-site, the time it took, the percent difference from the baseline. This call-site doesn't show us much potential for speed-up. It actually shows that if we speed up the select code, we might end up making our program slower.
The fourth column is a bit tricky. It is the percentage of samples that were detected within this call-site, scaled by the virtual speed-up. Roughly, it shows us the amount of speed-up we should expect if we were seeing this as a traditional profile.
Now for a more interesting call-site:
0x4478aa /home/daniel/go/src/runtime/stack.go:881 0% 2650250ns 5% 2659303ns +0.342% 0.84% 15% 2526251ns -4.68% 1.97% 45% 2434132ns -8.15% 6.65% 50% 2587378ns -2.37% 8.12% 55% 2405998ns -9.22% 8.31% 70% 2394923ns -9.63% 10.1% 85% 2501800ns -5.6% 11.7%
This call-site is within the stack growth code and shows that speeding it up might give us some decent results. The fourth column shows that we're essentially running this code as a critical section. With this in mind, let's look back at the traditional profile we collected, now focused on the stack growth code.
(pprof) top -cum newstack
Active filters:
focus=newstack
Showing nodes accounting for 1.44s, 1.77% of 81.55s total
Dropped 36 nodes (cum <= 0.41s)
Showing top 10 nodes out of 65
flat flat% sum% cum cum%
0.10s 0.12% 0.12% 8.47s 10.39% runtime.newstack
0.09s 0.11% 0.23% 8.25s 10.12% runtime.copystack
0.80s 0.98% 1.21% 7.17s 8.79% runtime.gentraceback
0 0% 1.21% 6.38s 7.82% net/http.(*http2serverConn).writeFrameAsync
0 0% 1.21% 4.32s 5.30% crypto/tls.(*Conn).Write
0 0% 1.21% 4.32s 5.30% crypto/tls.(*Conn).writeRecordLocked
0 0% 1.21% 4.32s 5.30% crypto/tls.(*halfConn).encrypt
0.45s 0.55% 1.77% 4.23s 5.19% runtime.adjustframe
0 0% 1.77% 3.90s 4.78% bufio.(*Writer).Write
0 0% 1.77% 3.90s 4.78% net/http.(*http2Framer).WriteData
This shows us that newstack is being called from writeFrameAsync. It is called in the goroutine that's spawned every time the HTTP/2 server wants to send a frame to the client. Only one writeFrameAsync can run at any given time and if a handler is trying to send more frames down the wire, it will be blocked until writeFrameAsync returns.
Because writeFrameAsync goes through several logical layers, it uses a lot of stack and stack growth is inevitable.
Speeding up the HTTP/2 server by 28.2% because I felt like it
If stack growth is slowing us down, then we should find some way of avoiding it. writeFrameAsync gets called on a new goroutine every time, so we pay the price of the stack growth on every frame write.
Instead, if we reuse the goroutine, we only pay the price of stack growth once and every subsequent write will reuse the now bigger stack. I made this modification to server and the causal profiling baseline turned from 2.650ms to 1.901ms, a reduction of 28.2%.
A bit caveat here is that HTTP/2 servers usually don't run full speed on localhost. I suspect if this was hooked up to the internet, the gains would be a lot less because the stack growth CPU time would get hidden in the network latency.
Conclusion
It's early days for causal profiling, but I think this small example does show off the potential it holds. If you want to play with causal profiling, you can check out my branch of the Go project with causal profiling added. You can also suggest other benchmarks for me to look at and we can see what comes from it.
P.S. I am currently between jobs and looking for work. If you'd be interested in working with low-level knowledge of Go internals and distributed systems engineering, check out my CV and send me an email on daniel@lasagna.horse.